

서버 장애 원인과 해결 전략: AWS·Cloudflare·AI 추론 서버까지 한눈에 보는 최신 가이드
서비스 품질을 좌우하는 핵심 인프라, 서버의 안정성과 확장성은 기업 경쟁력과 직결됩니다.
오늘날 클라우드 서버와 게임 서버, AI 서버까지 모든 디지털 서비스는 서버 상태에 따라 경험이 갈립니다.
오류 500 같은 내장 오류부터 CDN이나 DNS 이슈까지 원인은 다양하며, 다운타임을 줄이는 사전 대비가 중요합니다.
AWS EC2는 유연한 확장과 자원 할당으로 표준처럼 활용되며, 갑작스런 트래픽 급증에도 오토스케일링으로 대응합니다.
콘솔을 통한 상태 점검과 모니터링은 기본이며, 리전별 대시보드 확인으로 병목을 조기에 파악합니다.
비용과 성능 균형이 중요할 때는 서버 호스팅과 코로케이션 같은 옵션으로 네트워크 품질을 강화할 수 있습니다.
방화벽·모니터링·취약점 점검 등 보안 기본기를 제공하는 사업자를 선택하면 운영 리스크를 크게 낮출 수 있습니다.
Cloudflare 같은 CDN/WAF는 속도와 안전성을 끌어올리지만, 설정 오류나 정책 충돌로 접근 차단이 발생하기도 합니다.
challenges.cloudflare.com을 통한 봇 차단 메시지나 please unblock… to proceed 알림이 보인다면 WAF 규칙과 클라이언트 평판을 우선 점검합니다.
서버가 멀쩡해도 CDN·DNS·WAF 단에서의 이슈로 접근 불가 현상이 발생할 수 있습니다.
실제 점검에서는 네임서버 전파, 오리진 헬스체크, HTTP/2·HTTP/3 호환성을 함께 확인하는 것이 효율적입니다.
추가로 Downdetector 같은 외부 관측도구와 공급사 상태 페이지를 교차 검증하면 원인 축소에 도움이 됩니다.

운영 중 난제는 Server Fault 같은 전문가 Q&A에서 유사 사례를 확인하고 재현 조건을 좁히는 전략이 유용합니다.
로그 상의 타임아웃·메모리 누수·파일 디스크립터 한도는 빈번한 장애 유발 지점이므로 사전 튜닝을 권장합니다.
OpenAI Status와 같은 서비스 상태 대시보드는 외부 API 연동 서비스의 가용성을 파악하는 데 필수입니다.
챗봇·챗지피티·Gemini 등 AI 연동형 트래픽은 급등락이 잦아 서버 상태와 회로 차단기 패턴 구축이 안전합니다.

대기열 기반 서비스는 큐 길이와 채점 서버처럼 워커 풀 상태가 체감 성능을 좌우합니다.
스케줄러와 백프레셔를 설계해 큐 지연을 관리하면 사용자 체감 지연시간을 안정화할 수 있습니다.
게임 서버는 패치와 이벤트 시점에 접속 폭주가 발생하며, 리그오브레전드 서버나 ESO처럼 전용 서버 상태 페이지가 유용합니다.
클라이언트 오류가 체감될 때는 공식 상태 공지와 커뮤니티 리포트를 함께 확인하는 것이 빠른 판단에 도움이 됩니다.
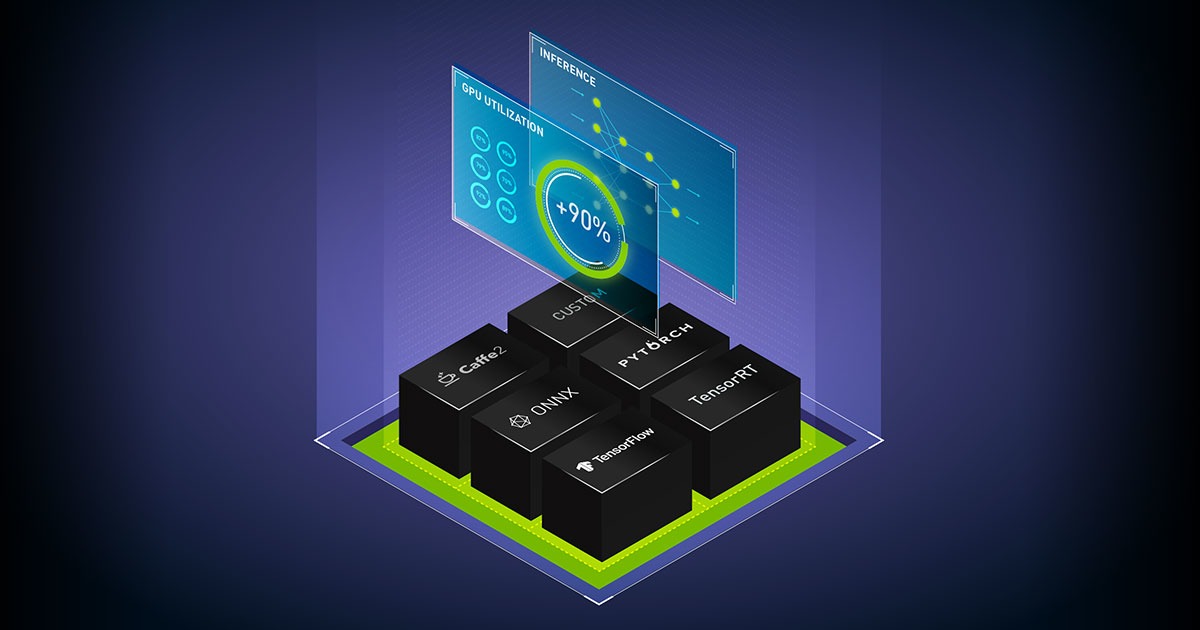
AI 시대에는 NVIDIA Triton Inference Server 같은 추론 서버가 표준화된 배포·실행을 돕습니다.
이식성과 멀티프레임워크 지원을 확보하면 CPU·GPU·가속기 조합에서 성능/비용 최적화를 이끌 수 있습니다.
스토리지와 네트워크 튜닝은 서버 성능의 마지막 퍼즐로, 엔터프라이즈 SSD와 RAID 구성이 지연시간 개선에 기여합니다.
캐시 정책·I/O 스케줄러·압축·TLS1.3 최적화를 병행하면 실효 처리량을 체감적으로 끌어올릴 수 있습니다.
장애 대응 체크리스트는 다음 순서가 효과적입니다.
1) 공급사 상태 페이지 확인 → 2) CDN/WAF 로그 점검 → 3) DNS·헬스체크 → 4) 오토스케일·리소스 한도 → 5) 애플리케이션 로그·큐 지연 분석입니다.
OpenAI Status, ESO 서버 상태처럼 공식 대시보드를 즐겨찾기하면 MTTR을 단축할 수 있습니다.
또한 Cloudflare 정책 변경 시에는 도메인별 예외 규칙과 봇 관리 기준을 정밀 조정해 오탐 차단을 최소화합니다.

